
As vSAN uses Ethernet to carry storage traffic, there are specific considerations that need to be considered when designing vSAN clusters, mainly when the number of hosts is not a few.
There was a performance issue in a newly-added all-flash cluster, where almost all VMs experienced latency over 1000ms with as little as 10 IOPS. When investigating the root cause, there was no symptom of latency on the backend disks both in the cache and capacity tier, no backend network latency, and overhead. We did a number of steps to troubleshoot. Although the compatibility list reported that all devices’ firmware is fully supported with vSAN, a couple of downgrades and upgrades with storage controller, network adapters, disks were done and tested accordingly. But that didn’t solve the problem. Again different ESXi builds were installed and it got us nowhere.
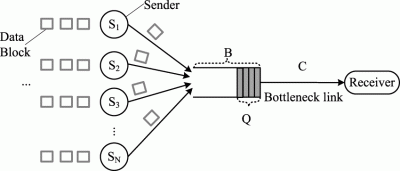
When investigating through physical switching infrastructure, we faced some TX Pause frames that leads to 200ms RTO (Retransmission Time Out). This is the actual root cause known as TCP incast problem. John Nicholson has a great blog on that.

just as a rule of thumb, when designing a vSAN cluster, consider using high buffer switching capacity and don’t go for FEX, Parrent topology. You will suffer performance issues, specifically, when the number of hosts increases as time goes on. I would like to refer you to another blog by John that has a great amount of information on vSAN network design.